Modular workflow system
Use smaller modules with clear jobs instead of one oversized workflow that gets annoying to maintain.
Portfolio Case Study
Building a modular SEO research pipeline using n8n, OpenAI, DataForSEO, and Google Sheets.
This project started with a pretty simple goal: make keyword research less messy without building a system that becomes its own problem later. The result is a modular workflow that collects, cleans, and structures SEO data so it can be used downstream for strategy, content planning, or GPT-assisted analysis.
1. The Problem
Manual keyword research tends to break down in very normal, very annoying ways. Data comes from too many places, formatting gets weird, and by the time you clean it up, you have already burned time you were trying to save.
It also gets harder to scale once the process depends too much on memory and cleanup habits. I wanted a workflow I could run repeatedly and trust, with structured output that was clean enough to use later for strategy, content planning, or GPT-assisted analysis.
2. Project Goals
Use smaller modules with clear jobs instead of one oversized workflow that gets annoying to maintain.
Build the flow once in a way that can support future research systems and content workflows.
Handle both direct seed keywords and wider niche exploration without rebuilding the system each time.
Produce structured data that is easy to work with later, not a stack of half-clean exports.
Leave room for clustering, prioritization, content planning, and brief generation later on.
Keep collection separate from strategy so the system stays flexible and easier to debug.
3. System Architecture
The system uses an orchestrator pattern. One main workflow coordinates the run, and each major step is handed off to a dedicated module. That keeps the responsibilities clear, makes failures easier to isolate, and lets me improve one part without disturbing the rest of the workflow.
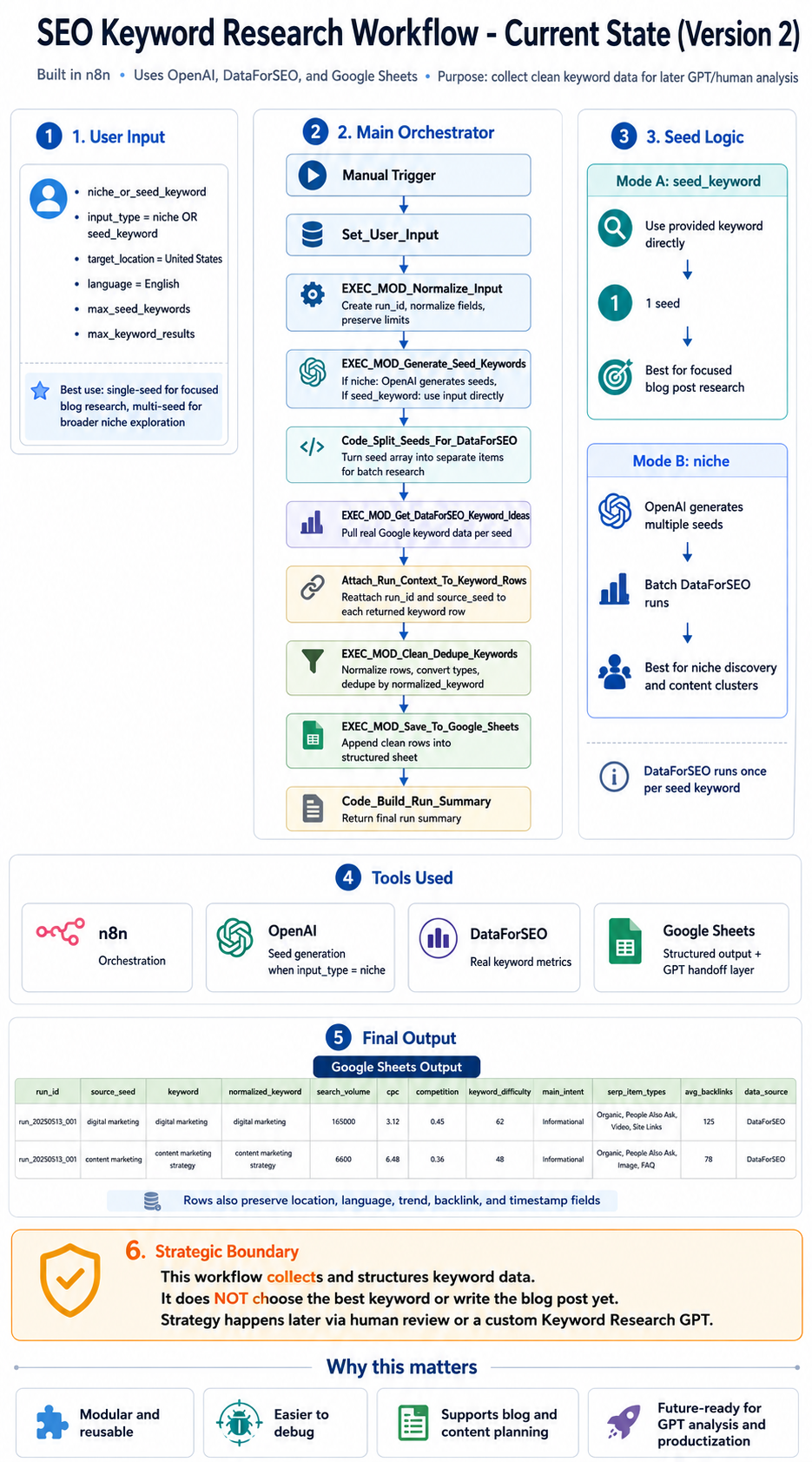
The real value here is separation of responsibilities. Input handling, seed generation, data retrieval, cleaning, export, and run summaries all live in their own layers. That makes the system easier to reuse and a lot easier to reason about when something changes.
4. Workflow Breakdown
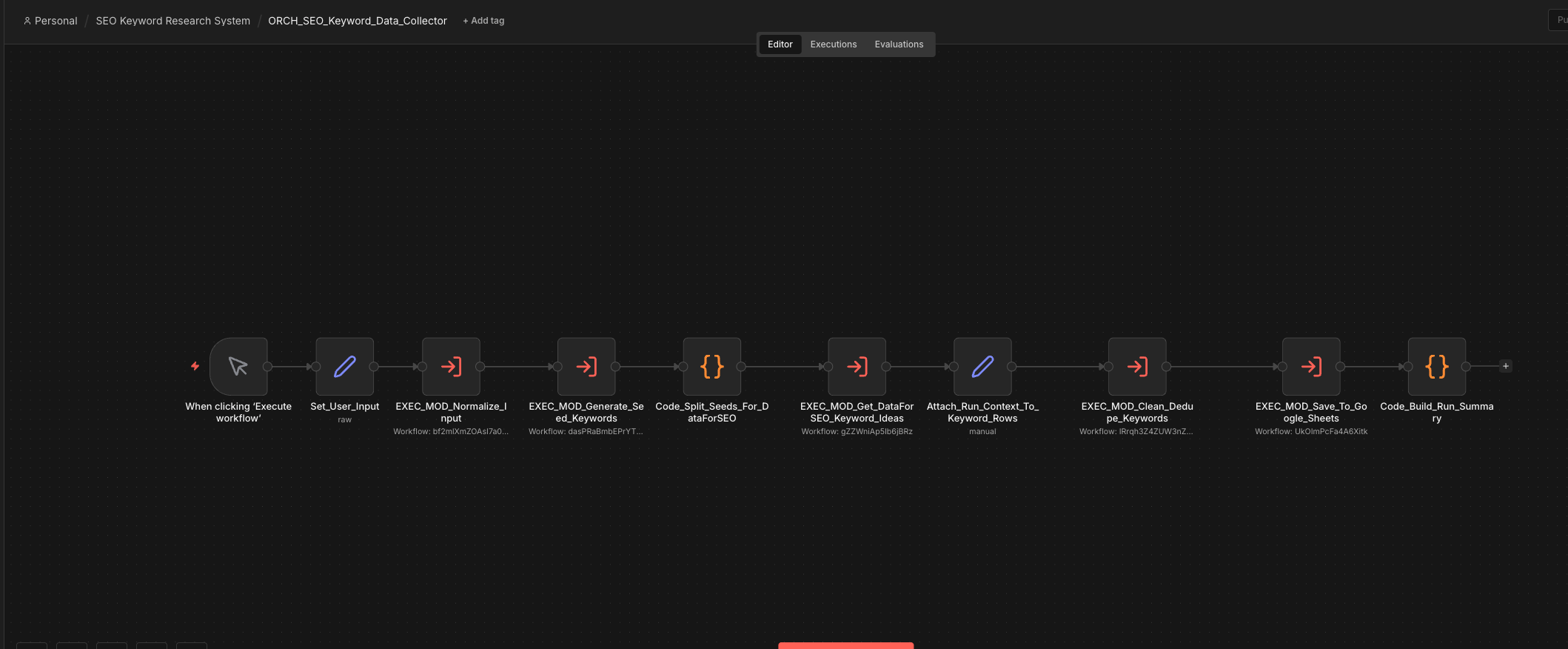
Every run starts by cleaning and standardizing the input. That includes limits, location, language, and input type, so the rest of the system is working with predictable values.
If the input is a niche, OpenAI generates seed terms. If the input is already a seed keyword, the workflow uses it directly. That split keeps the system flexible without making the later stages weird.
The workflow sends each seed through DataForSEO to pull real keyword metrics. This is where the process stops being conceptual and starts becoming a real dataset.
Returned rows are normalized, typed correctly, and deduplicated by normalized keyword values. Clean data is the difference between a workflow that scales and one that quietly creates more cleanup work for you later.
Once the dataset is clean, the workflow appends the results to a structured Google Sheet. That gives the system a stable handoff layer for later analysis, prioritization, or content planning.
Each execution ends with a run summary so it is easier to review what happened. That helps with logging, QA, and general sanity when the workflow gets used repeatedly.
5. Data Output Structure
The final sheet is structured so it can support later GPT analysis, human review, content planning, and prioritization. It is not just a raw dump. It is meant to be a usable working dataset.
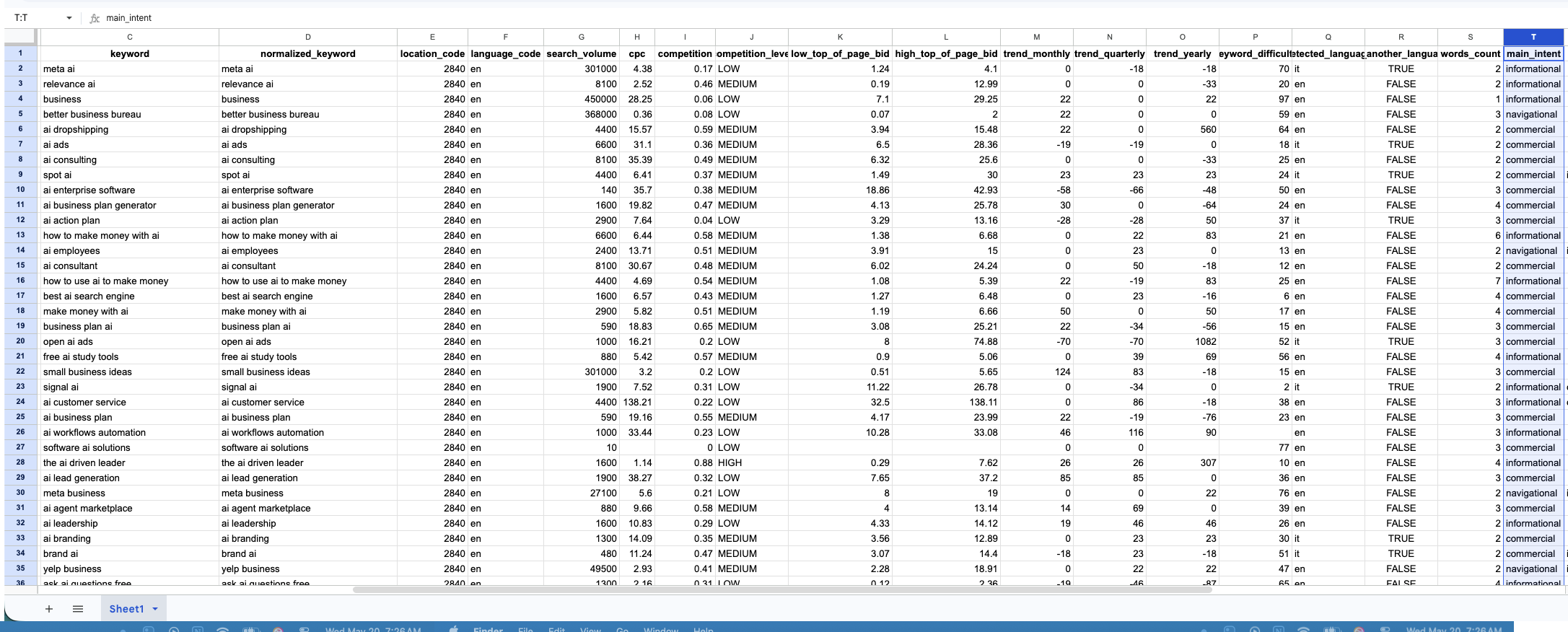
Search volume, CPC, competition, and top-of-page bid ranges.
Main intent fields make later filtering and content planning a lot easier.
Keyword difficulty makes prioritization easier when the dataset grows.
Clean structure makes later clustering, briefing, and analysis far more reliable.
6. Strategic Design Decisions
Modularity is not just a technical preference here. It is what makes the workflow easier to scale, easier to reuse, and much easier to debug when something breaks or changes.
Separating strategic analysis from data collection was another deliberate choice. The collection workflow is responsible for producing clean, structured inputs. It does not try to pick the best keyword, choose a content strategy, or write the brief. That keeps the system more flexible and makes it easier to connect to future analysis layers.
New modules can be added without turning the core workflow into a maintenance problem.
When a module fails, the problem area is much easier to isolate.
The same structure can support future SEO and research workflows without starting over.
7. Challenges and Lessons Learned
One of the bigger tensions in this project was balancing automation with strategic flexibility. It is very easy to keep stacking logic into a workflow because technically you can. That does not always make the workflow better.
The clearest lesson was that clean structure matters more than clever automation. If the data is inconsistent, the downstream work gets shakier. If the workflow tries to do too much, it gets harder to maintain and harder to trust.
The better path was to build a solid collection system first, keep the modules reusable, and leave room for human judgment where it still belongs.
8. Results and Impact
The collection process is much quicker and more repeatable than manual assembly.
The output is structured well enough to support later filtering, planning, and clustering work.
Each run produces a dataset that can be used again instead of a one-off export.
The architecture is ready for additional analysis layers without needing a rebuild later.
This is a practical example of systems design, not just a prompt experiment with a good screenshot.
9. Future Expansion
The current version is doing the right job for this stage. It collects and structures data well. The next step is using that data more intelligently without losing the clean boundaries that make the workflow useful in the first place.