Deterministic ingestion
Keep document identity, overwrite behavior, and chunk generation stable across repeated ingestion runs.
Portfolio Case Study
A modular AI retrieval and orchestration system designed for structured ingestion, grounded retrieval, and local AI experimentation.
Research Vault is a practical retrieval system build, not a vague AI concept. The project brings together ingestion workflows, document normalization, metadata handling, embeddings, vector search, and local model experimentation in a way that stays inspectable and maintainable as the system grows.
1. Project Overview
Research Vault is a modular AI knowledge retrieval system built to explore structured ingestion, grounded retrieval, and reusable orchestration patterns for AI-assisted knowledge workflows.
The system combines ingestion pipelines, document normalization, metadata processing, embeddings, vector retrieval, and local LLM integration in a way that is easier to reason about when things change. The core idea was simple: if retrieval is going to be useful, it also needs to be predictable enough to debug.
Instead of blending ingestion, prompting, and retrieval into one opaque workflow, the project was designed around explicit stage boundaries, deterministic behavior where possible, and contracts that can evolve without dragging the rest of the system with them.
2. The Problem
A lot of AI knowledge systems become harder to maintain once ingestion, embeddings, retrieval, and prompting logic start living in the same pile. A small inconsistency in document identity, chunking, metadata, or retrieval behavior can create downstream weirdness that is difficult to trace later.
I wanted to approach retrieval architecture more like infrastructure engineering: deterministic where possible, modular by design, explicit about contracts, and easier to evolve a little at a time.
The goal was not to build a flashy AI search demo. The goal was to build a cleaner retrieval foundation that could support real experimentation and future workflow systems without becoming fragile every time a new idea got added.
3. Project Goals
Keep document identity, overwrite behavior, and chunk generation stable across repeated ingestion runs.
Separate ingestion, processing, storage, and retrieval into workflow layers that can be maintained independently.
Favor retrieval-first context assembly and citation-aware behavior over invented confidence.
Use stable schema boundaries so workflows do not drift into slightly different versions of the same idea.
Support experiments with local models and infrastructure instead of relying entirely on hosted services.
Build patterns that can support future retrieval and knowledge systems beyond this one project.
4. System Architecture
The architecture was intentionally designed around modular workflow boundaries instead of one monolithic pipeline. Each layer handles one responsibility and passes validated contracts into the next stage.
Normalizes raw input into a stable internal schema with deterministic identity generation and routing metadata.
Cleans raw document text, performs deterministic chunking, validates contracts, and converts documents into chunk-level processing units.
Prepares embedding payloads, metadata contracts, enrichment layers, and stable vector storage structures.
Generates embeddings, stores vector payloads in Qdrant, and preserves deterministic overwrite behavior when content is reprocessed.
Handles query embedding, vector search, chunk retrieval, context assembly, grounded response generation, and fallback behavior when retrieval is weak.
Modularity ended up being one of the most important decisions in the project. Breaking the system into isolated stages made schema validation, debugging, and iteration much easier as the architecture evolved.
AI retrieval system built around workflow-oriented modular design.
Modular knowledge infrastructure for grounded querying and maintainable experimentation.
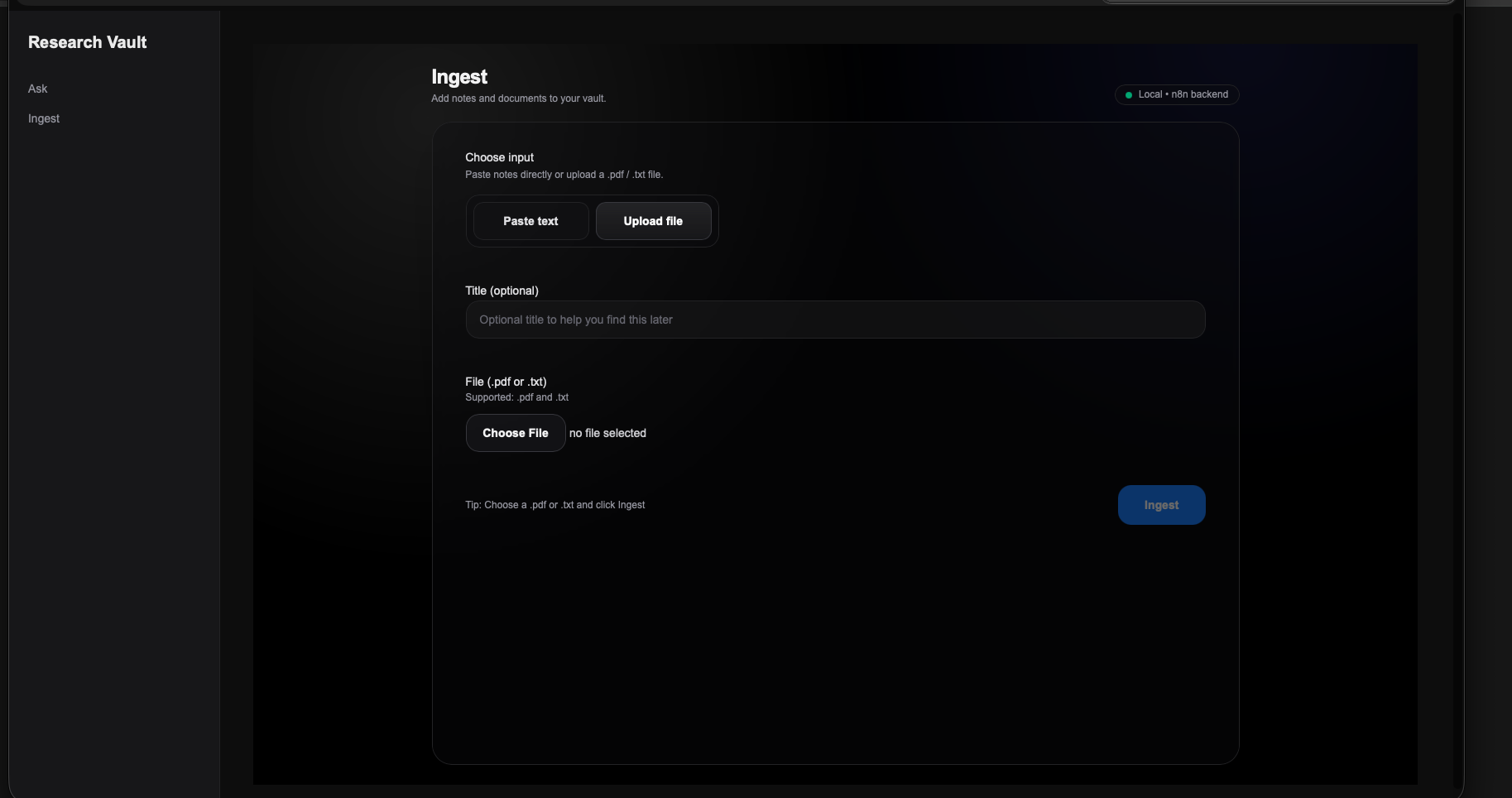
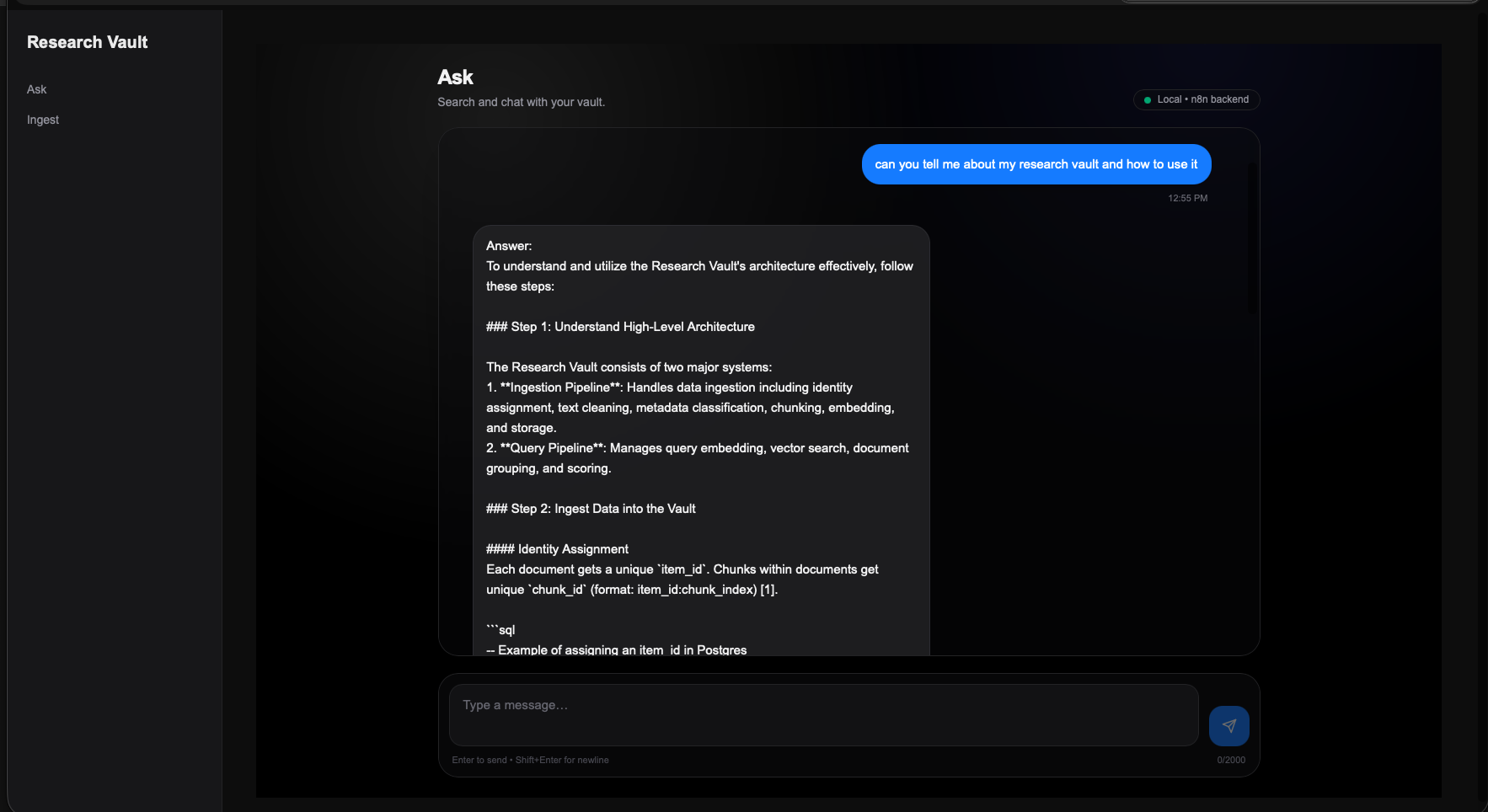
5. Frontend Experience
The frontend was intentionally kept lightweight. The point was to make the workflow usable without exposing every orchestration detail to the person using it.
The interface currently includes an ask surface, an ingest surface, PDF and text upload support, local backend connectivity, and straightforward conversational querying. The user flow is simple by design: ingest knowledge, structure retrieval, and ask for something useful back.
That split matters. A calmer interface makes it easier to use the system, while the orchestration layers do the work of normalization, routing, storage, and retrieval behind the scenes.
Supports direct text input and file upload so knowledge can enter the system without extra preparation steps.
Provides a conversational layer on top of retrieval without turning the UI into an overly clever dashboard.
6. Technical Stack
Workflow orchestration and coordination across ingestion, processing, and retrieval stages.
Vector storage for embeddings and semantic retrieval.
Structured relational storage for document identity, metadata, and chunk persistence.
Local model experimentation and grounded answer generation.
Embedding generation for retrieval indexing and query similarity.
Frontend delivery plus containerized local infrastructure for repeatable setup and testing.
7. Key Engineering Decisions
The system avoids random identifiers where it can. Re-ingesting the same content should overwrite predictably instead of quietly creating duplicates.
Stage boundaries use explicit contracts to freeze schemas and reduce drift between workflows over time.
Once chunk splitting happens, downstream processing stays at the chunk level. That makes retrieval logic clearer and reduces ambiguity across storage layers.
If retrieval does not return usable source material, the system avoids fabricated citations and falls back to a constrained assistant response.
External interfaces talk through webhook entry points so workflows remain modular and independently replaceable.
Local models and containerized infrastructure make debugging easier and reduce dependence on a fully hosted stack during development.
8. Lessons Learned
One of the most useful parts of this build was seeing how quickly retrieval systems become difficult to reason about without strong boundaries. Flexibility matters, but not if every layer starts making slightly different assumptions about the data.
Keeping workflows adaptable while preserving predictable behavior was one of the main balancing acts in the system.
A lot of downstream retrieval quality depends on ingestion consistency, chunk structure, and schema stability.
Isolated stages made it much easier to find failures, validate contracts, and iterate without breaking unrelated parts of the system.
Even with structured retrieval, grounding and orchestration are never completely solved. Fallback behavior and context handling still matter a lot.
A lot of the work in retrieval systems ends up looking less like clever prompting and more like careful systems engineering. That was not a disappointment. It was actually the point.
9. Project Summary
Research Vault demonstrates practical AI workflow engineering across modular orchestration, retrieval systems, ingestion architecture, vector search infrastructure, local AI experimentation, frontend and backend integration, and schema-driven workflow design.
The project is still evolving, but the foundation is already doing the work it was meant to do: provide a cleaner experimentation platform for grounded AI workflows and reusable orchestration patterns that can support future systems.